Aggregator#
Intoduction#
This section introduces the OIH approach to indexing. Currently, OIH is using the Gleaner software to do the indexing and leverages the Gleaner IO gleaner-compose Docker Compose files for the server side architecture. For more information on Docker Compose files visit the Overiew of Docker Compose. The gleaner-compose repository holds Docker compose files that can set up various environments that Gleaner needs.
The figure below gives a quick overview of the various compose options for setting up the supporting architecture for Gleaner. A fully configured system where all the indexing and data services are running and exposing services to the net, a total of five containers are run. In many case you may run fewer than this.
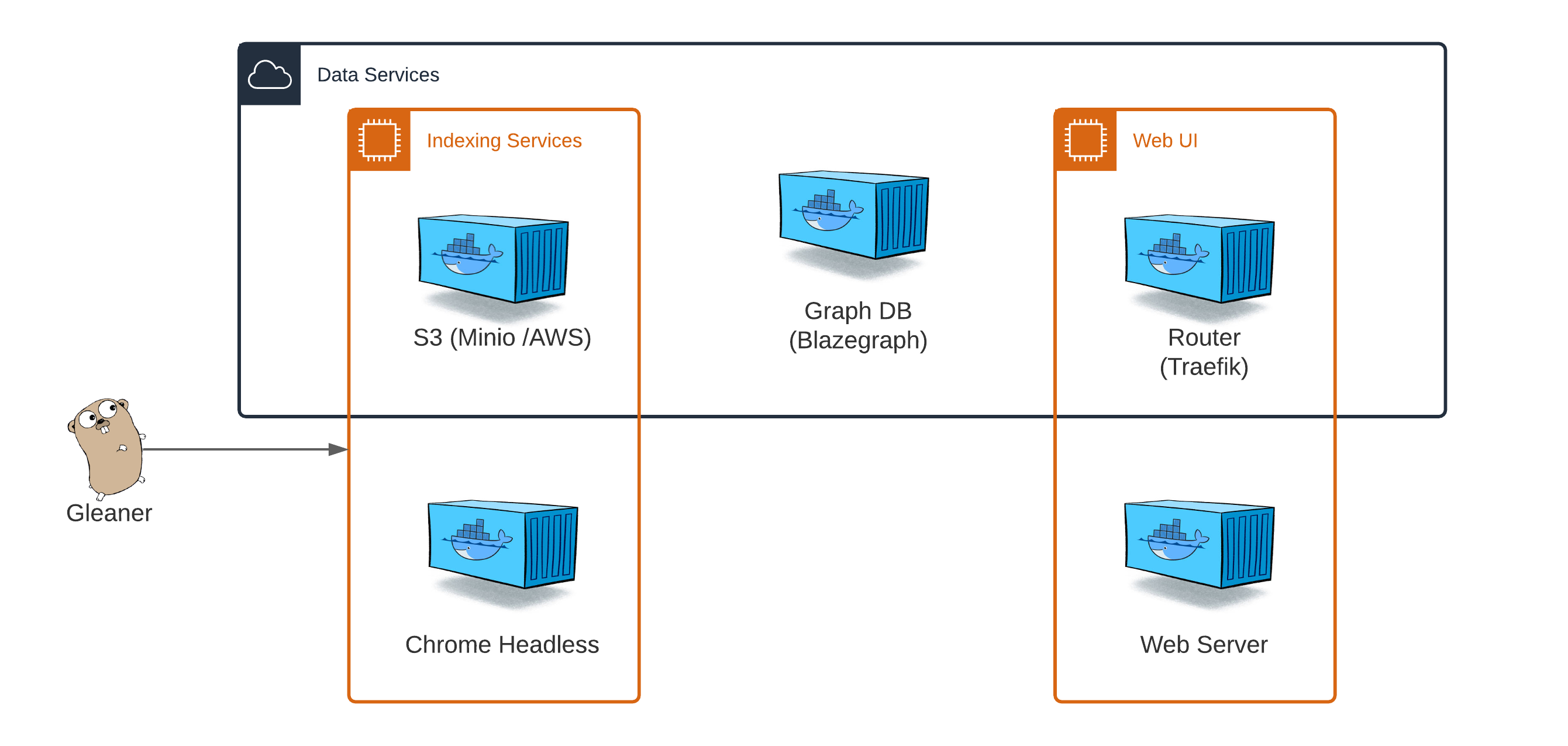
Fig. 1 The various compose options for Gleaner#
Container overview#
S3 (Minio / AWS): This is the only container that is required in all cases to run. Gleaner needs an S3 compatible object store. By default, we use the Minio object store
Chrome Headless: In cases where providers place the JSON-LD documents into the pages with Javascript, we need to render the page before reading and accessing the DOM. This is done using Chrome Headless
Graph database: Gleaner extracts JSON-LD documents from resources. These JSON-LD documents are representations of the RDF data mode. To queries on them at scale, it easiest to load the triples into a compatible graph database. Sometimes we call this a triplestore. For OIH we use the Blazgraph triplestore.
Router: If we wish to deploy this setup onto the net, we will route to route all the services through a single domain. To do this network routing we use Traefik. This router is not required for local use and alternative routers like Caffdy or nginx are also valid options.
Web Server: If you wish to serve a web UI for the index, then you can also leverage this setup to serve that. Again, this is optional and your web site may be hosted elswhere and simply call to the index in compliance with CORS settings. There is an example web server that leverages the object store available in this setup.
Gleaner#
As mentioned Gleaner is a single binary app (ie, one file). It can be run on Linux, Mac OS X or Windows. It does not need to be run on the same machine as the supporting services as it can connect to them over the network. So, for example, they could be hosted in commercial cloud services or on remote servers.
You can download and compile the code from the previously mentioned github repository or the releases page.
A single configuration file provides the settings Gleaner needs. Additionally, a local copy of the current schema.org context file should be downloaded and available to the app. This file is needed for many operations and access it over the net is slow and often rate limited depending on the source. You can download the file at the Schema.org for Developers page.
This setup show in the above figure is the typical setup for Gleaner and is detailed in the Quick Start section.
Indexing Services#
This is the basic indexing service requirements. At a minimum we need the object store and the Chrome headless containers scoped in the Indexing Sevices box above. More details on this set can be found in Indexing Servives.
Data Services#
A more expanded set of services is defined in the Data Services section. This section discussion a setup more designed to address a server setup tht will support indexing and also present the resulting indexes to the broader internet.
Web UI#
As mentioned, if you wish to serve a web UI for the index, then you can leverage this setup to serve that. Again, this is optional and your web site can be hosted elsewhere and simply call to the index in compliance with CORS settings.
Alternatives#
Note, the Gleaner ecosystem is not a requirement. OIH follows the structured data on the web and data on the web best practices patterns. Being web architecture based, there are many open source tools and scripting solutions you might use. You may wish to explore the Alternative Approaches section for more on this.
What follows is a bit more detail on the setup used by Gleaner. Experienced users will see where they can swap out elements for their own preference. Like a different triplestore, or wish to leverage a commercial object store? Simply modify the architecture to do so.
ODIS Catalog as Index Source#
Before we discuss indexing source a key question is what source will be indexed. OIH is not a web crawl in that it doesn’t move from source to source based on the content of those sources.
Rather, the OIH index is based on a list of sources selected ahead of time. At this time that set of sources if based on those partners engaged in the development phase of OIH. As the work moves to a more routine operation the sources will come from the ODIS Catalog.
The ODIS Catalog will then act as a curated source of domains for inclusion in the Ocean InfoHub. This will provide a level of curation and vetted of sources and ensure sources are aware of the technical requirements for inclusion in the OIH index.